|
СПЕЦІАЛЬНІ ПАРТНЕРИ ПРОЕКТУ BEST CIOОпределение наиболее профессиональных ИТ-управленцев, лидеров и экспертов в своих отраслях Человек годаКто внес наибольший вклад в развитие украинского ИТ-рынка. Продукт годаНаграды «Продукт года» еженедельника «Компьютерное обозрение» за наиболее выдающиеся ИТ-товары |
ABBYY FineReader 10: приоритет – распознавание фотоснимков
Автор – Елена Дериева, 22 октября 2009 г.
Статья опубликована в №36 (702) от 13 октября
После выпуска FineReader 9, в котором были пересмотрены принципы работы с многостраничными заданиями и реализована технология восстановления логической структуры документа, было трудно ожидать каких-то существенных новаций. Действительно, по большей части юбилейный релиз лишь развивает прежние идеи и технологии, однако ему есть чем удивить потенциального пользователя.
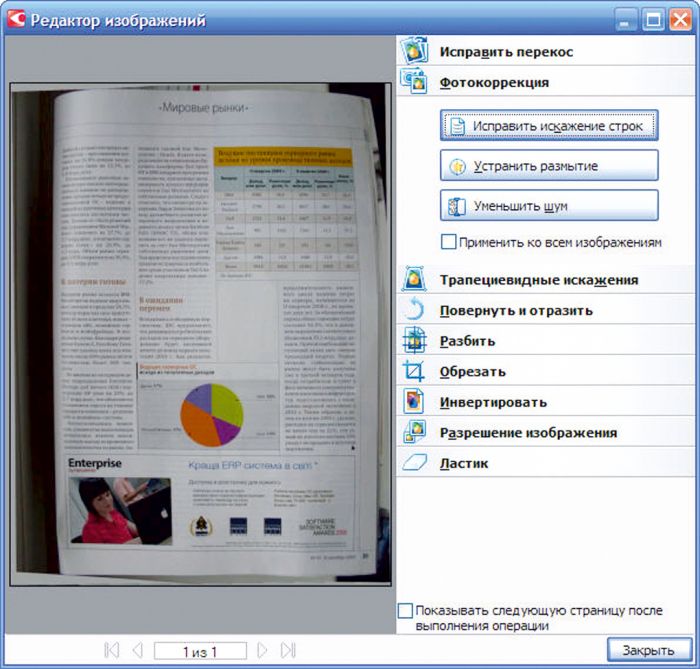
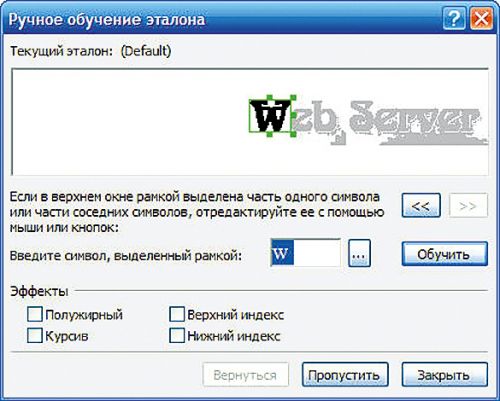
В FineReader 10 применяется второе поколение технологии ADRT – имен- но она отвечает за преобразование исходного изображения в логически сформированный документ (в котором идентифицированы и вымечены соответствующими стилями заголовки, колонтитулы, сноски и пр.). «Взросление» выразилось, скажем, в способности воссоздавать иерархические заголовки и строить на их основе оглавления, а также в более корректной работе с другими элементами, например колонтитулами четных/нечетных страниц, подписями к рисункам и таблицам. Все они при сохранении результатов распознавания в Microsoft Word воспроизводятся в виде не просто текста, а соответствующих объектов. Кроме того, в FineReader 10 существенно улучшено распознавание текста на фоне рисунков. Заметим, что и предыдущая версия справлялась с этой задачей неплохо, настолько, что в отдельных случаях приходилось вручную вымечать, скажем, снимки экрана, чтобы избежать распознавания текста на них. Новый же релиз намного корректнее обрабатывает вертикальный и инвертированный текст в автоматическом режиме, а если ориентация или светлый текст на темной подложке идентифицированы неверно, имеются инструменты, которые позволяют вручную изменить параметры отдельного блока и повторить операцию. Усовершенствована также работа с декоративными шрифтами и специальными символами, причем для улучшения качества в данном случае можно на начальном этапе использовать режим «Распознавание с обучением», в процессе которого накапливаются эталоны букв – впоследствии их можно будет применять для автоматической обработки основного объема входящих изображений. Благодаря этому повышается качество воссоздания документов со сложным оформлением, например буклетов и глянцевых журналов.
Еще одно направление эволюции FineReader 10 – улучшение качества распознавания оригиналов в низком разрешении: факсов, фотографий и пр. По оценкам ABBYY, около 40% пользователей цифровых фотокамер когда-либо сталкивались с распознаванием сделанных с их помощью снимков, на качество которых, впрочем, прежде налагались сравнительно жесткие требования. Нынешняя версия, по данным разработчиков, распознает документы с низким разрешением на 30% лучше, чем предыдущая (в общем, это подтвердилось в наших тестах, хотя количественную оценку мы не проводили), за счет усовершенствований как собственно OCR-технологий, так и новых функций предварительной подготовки. В принципе, программа автоматически определяет и выполняет необходимые процедуры исправления перекосов, выравнивания строк, коррекции объемных искажений, перспективы, устранения цифрового «шума» и размытости, возникающей вследствие дрожания руки при съемке, однако в отдельных случаях некоторые виды коррекции можно произвести вручную. Такая обработка действительно повышает качество распознавания документов (хотя при хорошем исходном материале от нее можно отказаться в целях экономии времени), настолько, что FineReader 10 без особых проблем справляется, к примеру, с фотоснимками журнальных страниц (вплоть до формата А4) разрешением всего 2 Мп. Соответственно, для оригиналов меньшего размера можно применять даже более слабую технику.
На первый взгляд, это открывает путь к использованию камер мобильных телефонов для съемки, например, проспектов, буклетов и пр. в походных условиях с целью последующего распознавания. Однако на поверку оказалось не совсем так. Дело в том, что, как правило, камеры сотовых аппаратов (более специализированные «камерофоны» в расчет не берем) имеют фиксированный фокус, низкую разрешающую способность объектива (независимо от количества мегапикселов), невысокую светочувствительность и просто не позволяют получить с маленького расстояния снимки достаточной четкости, тем более при сложном освещении. Соответственно, распознавание снимков со среднестатистического мобильного возможно лишь теоретически, разве только плакатов и других сравнительно крупных объектов, снятых с большого расстояния. При этом даже самая простая цифровая фотокамера с регулируемой фокусировкой позволяет «с рук» (т. е. без использования штатива) получать пригодные для работы FineReader 10 снимки размером хоть 1 Мп. Кроме того, ряд дополнительных функций дает возможность применять FineReader 10 для решения смежных задач, к примеру для превращения бумажных книг в электронные, включая предназначенные для чтения на специализированных устройствах. Для этого программа умеет не только разделять несколько страниц, попавших на одно изображение, в том числе и в автоматическом режиме (с чем не справлялась предыдущая версия), но и позволяет сохранять главы в отдельные HTML-файлы с последующим восстановлением ссылок на них из содержания.
Вообще идеология FineReader 10 направлена на то, чтобы максимум работы выполнять автоматически. Для этого в приложении теперь есть новые встроенные сценарии, охватывающие наиболее распространенные задачи по распознаванию исходных данных из PDF-документов, файлов изображений, цифровых фото или отсканированных документов. Для настройки их параметров появились специальное окно и новые панели инструментов, хотя во многих случаях в этом нет необходимости и задание можно выдавать прямо из Windows Explorer. Тем не менее интерфейс программы осовременен и оформлен с помощью набирающих популярность «лент», а опытным пользователям определенно понравится возможность настройки «горячих» клавиш. Как и ранее, полученный в результате распознавания документ можно передать и в Microsoft Word, и в OpenOffice.org Writer, а также сохранить в PDF. Кстати, спектр доступных действий с последним форматом заметно расширен, аналогично тому, как это сделано в PDF Transformer 3 (ko-online.com.ua/43227). FineReader 10 умеет открывать PDF-файлы, сохранять результаты распознавания в PDF либо архивный PDF/A с возможностью поиска (текст под и над изображением, только текст и картинки, только изображение), поддерживает защиту с помощью пароля (от несанкционированного открытия, редактирования, печати и даже копирования содержимого с экрана ПК) и шифрования. Технология MRC (Mixed Raster Content) за счет применения разных алгоритмов сжатия для текста и изображений позволяет сократить размеры результирующих файлов в несколько раз без потери качества и наиболее актуальна при обработке цветных документов. Решения ABBYY традиционно отличаются качественной лингвистической поддержкой, в FineReader 10 число языков распознавания достигло 186, впервые появились корейский и идиш, а для 39 наиболее популярных языков (включая русский) есть проверка орфографии. По оценке ABBYY, качество «понимания» текстов на азиатских языках улучшилось на 30%, а на европейских – на 20%. Кроме того, в программе предусмотрена возможность формирования наборов языков для работы с многоязычными документами – это позволяет в некоторых случаях избежать путаницы и ускорить получение результата. Стратегія охолодження ЦОД для епохи AI
Читайте также
|
Останні обговорення
ТОП-новини
ТОП-блогиТОП-статті
|
|||||||||||||||||||